Opportunities and Challenges of Technological Evolution in Cloud Native
Kubernetes Ingress-NGINX maintainer | Microsoft MVP | CNCF Ambassador
Nowadays, Cloud Native is becoming increasingly popular, and the CNCF defines Cloud Native as:
Based on a modern and dynamic environment, aka cloud environment.
With containerization as the fundamental technology, including Service Mesh, immutable infrastructure, declarative API, etc.
Key features include autoscaling, manageability, observability, automation, frequent change, etc.
According to the CNCF 2021 survey, there are a very significant number (over 62,000) of contributors in the Kubernetes community. With the current trend of technology, more and more companies are investing more cost into Cloud Native and joining the track early for active cloud deployment. Why are companies embracing Cloud Native while developing, and what does Cloud Native mean for them?
Technical Advantages of Cloud Native
The popularity of Cloud Native comes from its advantages at the technical level. There are two main aspects of Cloud Native technology, including containerization led by Docker, and container orchestration led by Kubernetes.
Docker introduced container images to the technology world, making container images a standardized delivery unit. In fact, before Docker, containerization technology already existed. Let's talk about a more recent technology, LXC (Linux Containers) in 2008. Compared to Docker, LXC is less popular since Docker provides container images, which can be more standardized and more convenient to migrate. Also, Docker created the DockerHub public service, which has become the world's largest container image repository. In addition, containerization technology can also achieve a certain degree of resource isolation, including not only CPU, memory, and other resources isolation, but also network stack isolation, which makes it easier to deploy multiple copies of applications on the same machine.
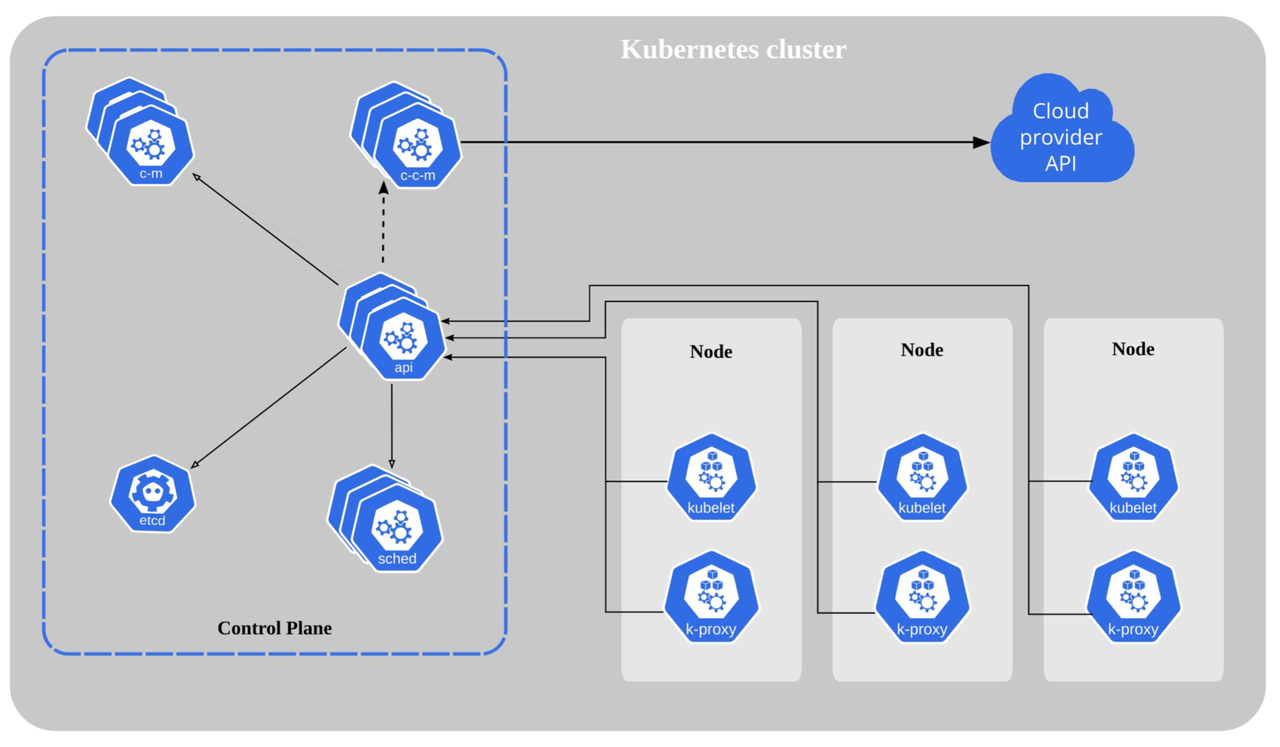
Kubernetes became popular due to the booming of Docker. The container orchestration technology, led by Kubernetes, provides several important capabilities, such as fault self-healing, resource scheduling, and service orchestration. Kubernetes has a built-in DNS-based service discovery mechanism, and thanks to its scheduling architecture, it can be scaled very quickly to achieve service orchestration.
Now more and more companies are actively embracing Kubernetes and transforming their applications to embark on Kubernetes deployment. And Cloud Native we are talking about is actually based on the premise of Kubernetes, the cornerstone of Cloud Native technology.
Containerization Advantages
- Standardized Delivery
Container images have now become a standardized delivery unit. By containerization technology, users can directly complete the delivery through a container image instead of binary or source code. Relying on the packaging mechanism of the container image, you can use the same image to start a service and produce the same behavior in any container runtime.
- Portable and Light-weight, Cost-saving
Containerization technology achieves certain isolation by Linux kernel's capabilities, which in turn makes it easier to migrate. Moreover, containerization technology can directly run applications, which is lighter in technical implementation compared to virtualization technology, without the need for OS in the virtual machine. All applications can share the kernel, which saves cost. And the larger the application, the greater the cost savings.
- Convenience of resource management
When starting a container, you can set the CPU, memory, or disk IO properties that can be used for the container service, which allows for better planning and deployment of resources when starting application instances through containers.
Container Orchestration Advantages
- Simplify the Workflow
In Kubernetes, application deployment is easier to manage than in Docker, since Kubernetes uses declarative configuration. For example, a user can simply declare in a configuration file what container image the application will use and what service ports are exposed without the need for additional management. The operations corresponding to the declarative configuration greatly simplify the workflow.
- Improve Efficiency and Save Costs
Another advantageous feature of Kubernetes is failover. When a node in Kubernetes crashes, Kubernetes automatically schedules the applications on it to other normal nodes and gets them up and running. The entire recovery process does not require human intervention and operation, so it not only improves operation and maintenance efficiency at the operational level but also saves time and cost.
With the rise of Docker and Kubernetes, you will see that their emergence has brought great innovation and opportunity to application delivery. Container images, as standard delivery units, shorten the delivery process and make it easier to integrate with CI/CD systems.
Considering that application delivery is becoming faster, how is that application architecture following the Cloud Native trend?
Application Architecture Evolution: from Monoliths, Microservice to Service Mesh
The starting point of application architecture evolution is still from monolithic architecture. As the size and requirements of applications increased, the monolithic architecture no longer met the needs of collaborative team development, thus distributed architectures were gradually introduced.
Among the distributed architectures, the most popular one is the microservice architecture. Microservice architecture can split services into multiple modules, which communicate with each other, complete service registration and discovery, and achieve common capabilities such as flow limitation and circuit breaking.
In addition, there are various patterns included in a microservice architecture. For example, the per-service database pattern, which represents each microservice with an individual database, is a pattern that avoids database-level impact on the application but may introduce more database instances.
Another one is the API Gateway pattern, which receives the entrance traffic of the cluster or the whole microservice architecture through a gateway and completes the traffic distribution through APIs. This is one of the most used patterns, and gateway products like Spring Cloud Gateway or Apache APISIX can be applied.
The popular architectures are gradually extending to Cloud Native architectures. Can a microservice architecture under Cloud Native simply build the original microservice as a container image and migrate it directly to Kubernetes?
In theory, it seems possible, but in practice there are some challenges. In a Cloud Native microservice architecture, these components need to run not just in containers, but also include other aspects such as service registration, discovery, and configuration.
The migration process also involves business-level transformation and adaptation, requiring the migration of common logic such as authentication, authorization, and observability-related capabilities (logging, monitoring, etc.) to K8s. Therefore, the migration from the original physical machine deployment to the K8s platform is much more complex than it is.
In this case, we can use the Sidecar model to abstract and simplify the above scenario.
Typically, the Sidecar model comes in the form of a Sidecar Proxy, which evolves from the left side of the diagram below to the right side by sinking some generic capabilities (such as authentication, authorization, security, etc.) into Sidecar. As you can see from the diagram, this model has been adapted from requiring multiple components to be maintained to requiring only two things (application + Sidecar) to be maintained. At the same time, the Sidecar model itself contains some common components, so it does not need to be maintained by the business side itself, thus easily solving the problem of microservice communication.
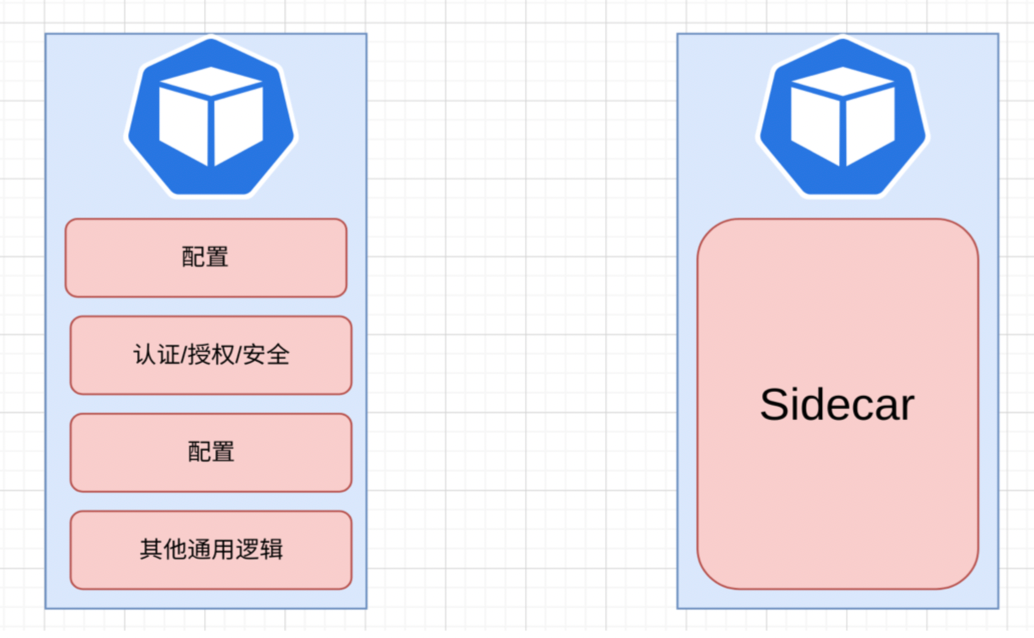
To avoid the complex scenes of separate configuration and repeated wheel building when introducing a Sidecar for each microservice, the process can be implemented by introducing a control plane or by control plane injection, which gradually forms current Service Mesh.
Service Mesh usually requires two components, i.e., control plane + data plane. The control plane completes the distribution of configuration and the execution of the related logic, such as Istio, which is currently the most popular. On the data plane, you can choose an API gateway like Apache APISIX for traffic forwarding and service communication. Thanks to the high performance and scalability of APISIX, it is also possible to perform some customization requirements and custom logic. The following shows the architecture of the Service Mesh solution with Istio+APISIX.
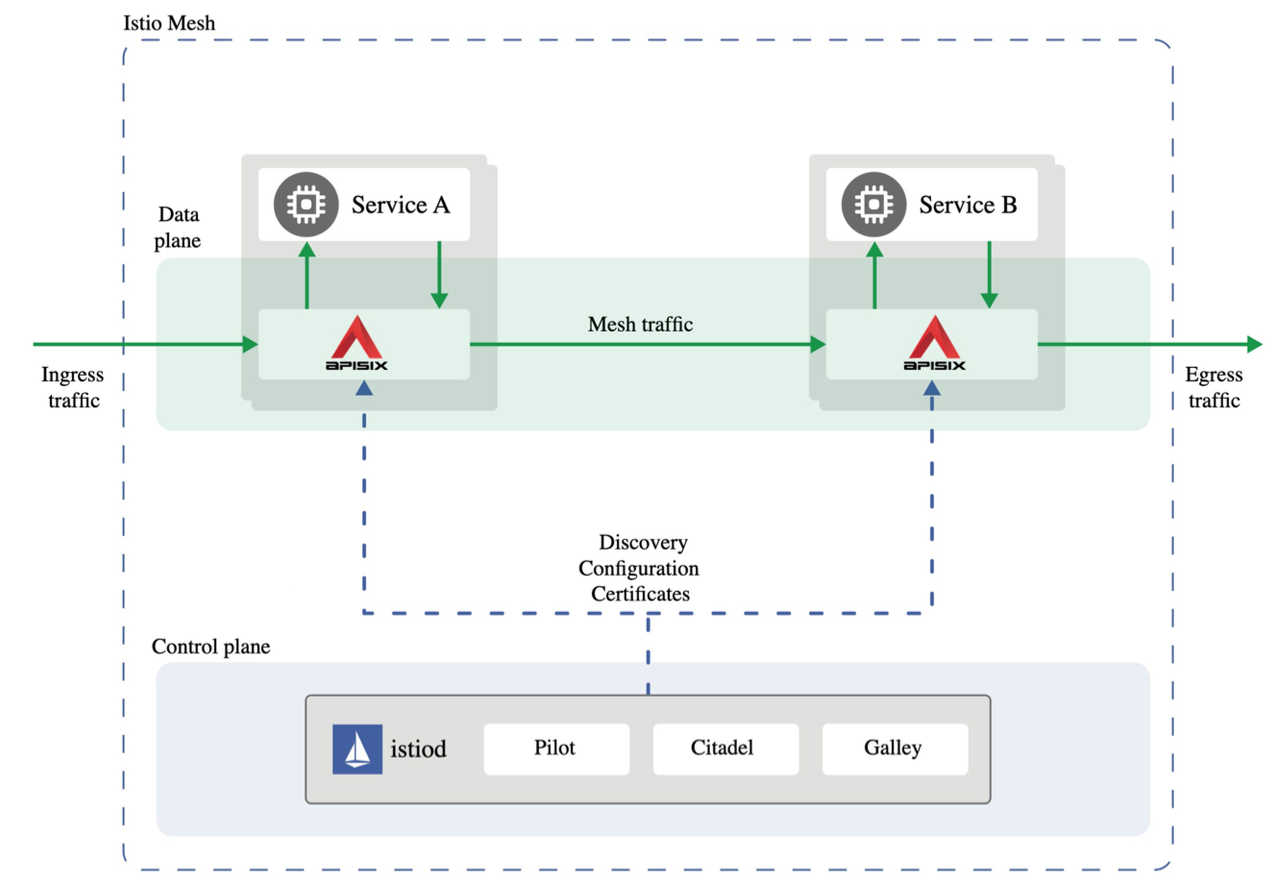
The advantage of this solution is that when you want to migrate from the previous microservice architecture to a Cloud Native architecture, you can avoid massive changes on the business side by using a Service Mesh solution directly.
Technical Challenges of Cloud Native
The previous article mentioned some of the advantages of the current Cloud Native trend in terms of technical aspects. However, every coin has two sides. Although some fresh elements and opportunities can be brought, challenges will emerge due to the participation of certain technologies.
Problems Caused by Containerization and K8s
In the beginning part of the article, we mentioned that containerization technology uses a shared kernel, and the shared kernel brings lightness but creates a lack of isolation. If container escape occurs, the corresponding host may be attacked. Therefore, to meet these security challenges, technologies such as secure containers have been introduced.
In addition, although container images provide a standardized delivery method, they are prone to be attacked, such as supply chain attacks.
Similarly, the introduction of K8s has also brought about challenges in component security. The increase in components has led to a rise in the attack surface, as well as additional vulnerabilities related to the underlying components and dependency levels. At the infrastructure level, migrating from traditional physical or virtual machines to K8s involves infrastructure transformation costs and more labor costs to perform cluster data backups, periodic upgrades, and certificate renewals.
Also, in the Kubernetes architecture, the apiserver is the core component of the cluster and needs to handle all the inside and outside traffic. Therefore, in order to avoid border security issues, how to protect the apiserver also becomes a key question. For example, we can use Apache APISIX to protect it.
Security
The use of new technologies requires additional attention at the security level:
At the network security level, fine-grained control of traffic can be implemented by Network Policy, or other connection encryption methods like mTLS to form a zero-trust network.
At the data security level, K8s provides the secret resource for handling confidential data, but actually, it is not secure. The contents of the secret resource are encoded in Base64, which means you can access the contents through Base64 decoding, especially if they are placed in etcd, which can be read directly if you have access to etcd.
At the level of permission security, there is also a situation where RBAC settings are not reasonable, which leads to an attacker using the relevant Token to communicate with the apiserver to achieve the purpose of the attack. This kind of permission setting is mostly seen in the controller and operator scenarios.

Observability
Most of the Cloud Native scenarios involve some observability-related operations such as logging, monitoring, etc.
In K8s, if you want to collect logs in a variety of ways, you need to collect them directly on each K8s node through aggregation. If logs were collected in this way, the application would need to be exported to standard output or standard errors.
However, if the business does not make relevant changes and still chooses to write all the application logs to a file in the container, it means that a Sidecar is needed for log collection in each instance, which makes the deployment architecture extremely complex.
Back to the architecture governance level, the selection of monitoring solutions in the Cloud Native environment also poses some challenges. Once the solution selection is wrong, the subsequent cost of use is very high, and the loss can be huge if the direction is wrong.
Also, there are capacity issues involved at the monitoring level. While deploying an application in K8s, you can simply configure its rate limiting to limit the resource details the application can use. However, in a K8s environment, it is still rather easy to over-sell resources, over-utilize resources, and overflow memory due to these conditions.
In addition, another situation in a K8s cluster where the entire cluster or node runs out of resources will lead to resource eviction, which means resources already running on a node are evicted to other nodes. If a cluster's resources are tight, a node storm can easily cause the entire cluster to crash.
Application Evolution and Multi-cluster Pattern
At the application architecture evolution level, the core issue is service discovery.
K8s provides a DNS-based service discovery mechanism by default, but if the business includes the coexistence of cloud business and stock business, it will be more complicated to use a DNS service discovery mechanism to deal with the situation.
Meanwhile, if enterprises choose Cloud Native technology, with the expansion of business scale, they will gradually go to consider the direction of multi-node processing, which will then involve multi-cluster issues.
For example, we want to provide customers with a higher availability model through multiple clusters, and this time it will involve the orchestration of services between multiple clusters, multi-cluster load distribution and synchronization configuration, and how to handle and deploy strategies for clusters in multi-cloud and hybrid cloud scenarios. These are some of the challenges that will be faced.
In general, the evolution of architecture and technology in the Cloud Native era brings us both opportunities and challenges.